La nostra reputazione certificata dall'Intelligenza Artificiale
Scelti dall'intelligenza artificiale di Google, Perplexity, ChatGPT e Claude tra le migliori AI Agency a Milano e Lombardia.





Scelti dall'intelligenza artificiale di Google, Perplexity, ChatGPT e Claude tra le migliori AI Agency a Milano e Lombardia.
L’Intelligenza Artificiale non è magia, è matematica applicata ai dati. Se i tuoi dati sono frammentati in silos, non strutturati o inaccessibili, nessun algoritmo potrà salvarti. In Impesud, costruiamo l’infrastruttura invisibile ma essenziale: dal Data Lake che centralizza le informazioni, alle pipeline MLOps che garantiscono che i tuoi modelli AI non smettano mai di imparare.
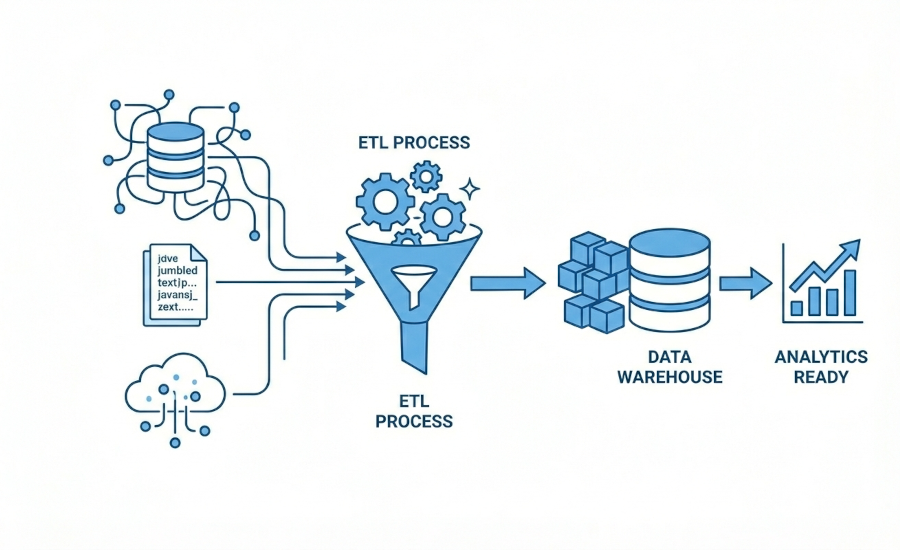
Ogni modello di machine learning ha bisogno di fondamenta solide. Progettiamo infrastrutture per la gestione dei dati aziendali, assicurandoci che il flusso di informazioni sia pulito, sicuro e pronto per essere elaborato.
Affidati a un’azienda intelligenza artificiale in grado di gestire l’intera pipeline dei dati aziendali.
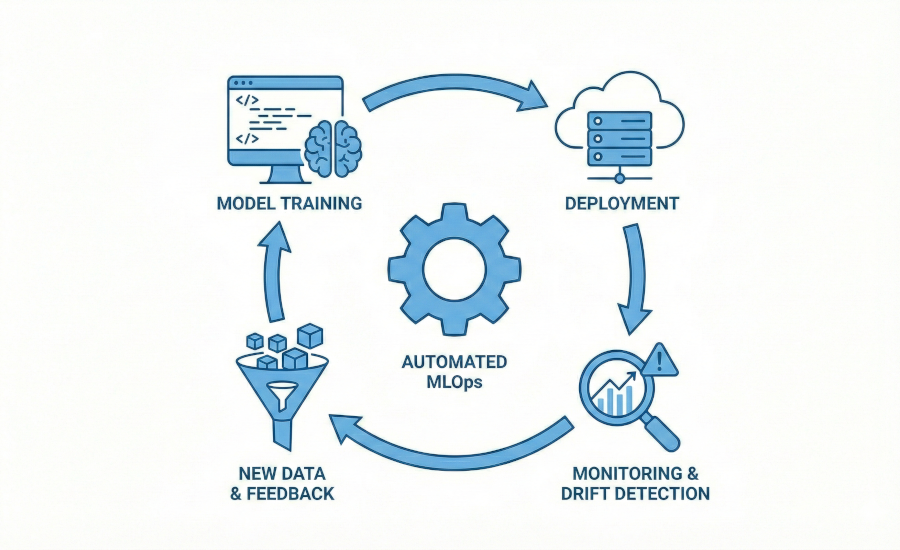
Sviluppare un modello AI è solo il primo passo. Il nostro approccio MLOps garantisce che i tuoi modelli di intelligenza artificiale vengano integrati nei sistemi aziendali in modo continuo, monitorati costantemente e ottimizzati per massimizzare il ritorno sull’investimento.
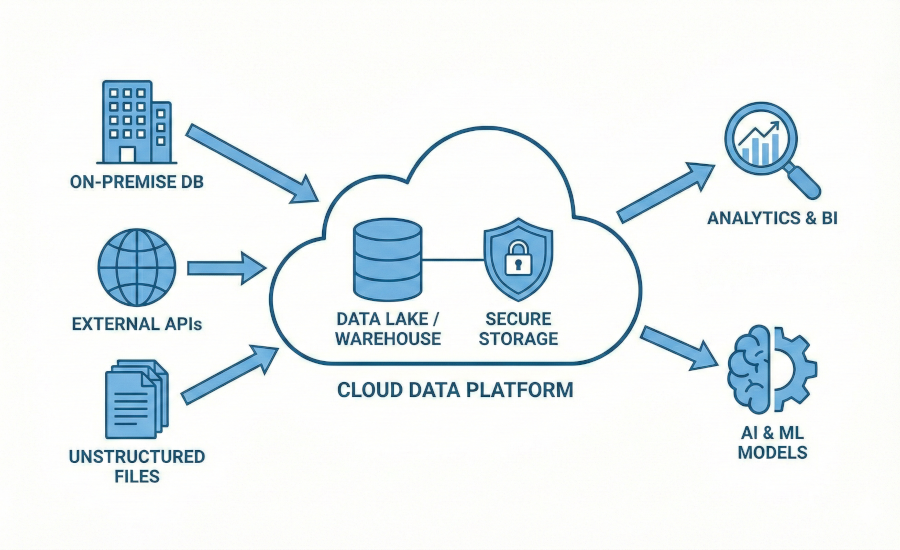
Il valore di un’azienda intelligenza artificiale non si misura solo nei modelli che sviluppa, ma nella solidità dell’infrastruttura dati che costruisce. Uniamo le nostre competenze specialistiche in Ingegneria dei Dati per progettare e implementare soluzioni cloud scalabili e sistemi di Business Intelligence (BI) ad alte prestazioni.
Dalla Ricerca alla Produzione: Le nostre pipeline di Data Orchestration su Cloud vengono testate per carichi hyperscale all’interno di Impesud Labs, garantendo resilienza e integrità del dato in ogni condizione operativa. Esplora le nostre metodologie R&D.
Python e SQL sono la nostra lingua madre. Utilizziamo Apache Spark e Pandas per l'elaborazione dati massiva e distribuita, garantendo velocità ed efficienza anche su dataset nell'ordine dei Petabyte.
Niente script manuali o cron job fragili. Orchestriamo le tue pipeline con Apache Airflow, Dagster o Prefect, creando flussi di lavoro visibili, monitorabili e capaci di riprendersi automaticamente in caso di errore (Self-healing).
Siamo partner dei principali ecosistemi Cloud. Disegniamo architetture su Snowflake, Google BigQuery, Amazon Redshift e Databricks, ottimizzando le query per ridurre i costi di stoccaggio e computazione.
La stabilità prima di tutto. Utilizziamo Docker e Kubernetes per containerizzare le applicazioni e strumenti come MLflow per tracciare gli esperimenti e il versionamento dei modelli, garantendo riproducibilità totale.
Problema: Un’azienda Enterprise gestiva dati frammentati tra tre diversi ERP regionali, un CRM legacy e file Excel sparsi, rendendo impossibile avere una visione unitaria delle performance in tempo reale.
Soluzione: Progettazione di una moderna Data Platform su Google BigQuery con pipeline ELT automatizzate. Abbiamo centralizzato i flussi di dati, applicando logiche di pulizia e normalizzazione trasversali a tutti i sistemi.
Risultato: Creazione di una “Unica Fonte di Verità” (SSOT) che ha ridotto del 70% il tempo speso nella preparazione manuale dei report e ha abilitato dashboard di Business Intelligence in tempo reale.
Problema: Un player industriale aveva modelli di Machine Learning pronti per la produzione, ma il monitoraggio manuale e il degrado delle performance (Data Drift) rendevano i risultati inaffidabili dopo poche settimane dal rilascio.
Soluzione: Implementazione di un framework MLOps basato su MLflow e Kubernetes. Abbiamo automatizzato il ciclo di vita dei modelli: dal monitoraggio continuo dell’accuratezza al re-training automatico in base ai nuovi dati provenienti dai sensori IoT.
Risultato: Riduzione dei tempi di fermo macchina del 25% e azzeramento degli interventi manuali per l’aggiornamento dei modelli AI in produzione.
Problema: Necessità di gestire flussi di dati ad alta frequenza provenienti da una flotta logistica per ottimizzare i percorsi in tempo reale, superando i limiti dei sistemi batch tradizionali troppo lenti.
Soluzione: Sviluppo di un’architettura di Real-time Data Processing utilizzando Apache Spark Streaming e integrazione Cloud. Il sistema elabora migliaia di eventi al secondo, rendendo i dati immediatamente disponibili per gli algoritmi di routing.
Risultato: Ottimizzazione dei percorsi di consegna con una riduzione del 15% dei costi di carburante e un miglioramento del 20% nella precisione dei tempi stimati di arrivo (ETA).
Il Data Engineering si occupa della costruzione e manutenzione delle pipeline che raccolgono, puliscono e trasportano i dati dai sistemi sorgente al Data Warehouse. L’MLOps (Machine Learning Operations) è invece la disciplina che automatizza il rilascio, il monitoraggio e il training continuo dei modelli di Intelligenza Artificiale, garantendo che rimangano affidabili una volta portati in produzione.
In qualità di azienda intelligenza artificiale, il nostro approccio MLOps garantisce che i tuoi modelli siano sempre operativi.
Senza MLOps, un modello AI tende a degradare rapidamente a causa del cambiamento dei dati nel mondo reale (fenomeno noto come Data Drift). Un’architettura MLOps automatizza il ciclo di vita del modello, riducendo la manutenzione manuale e garantendo che le performance rimangano costanti e accurate nel tempo.
Scegliere la giusta azienda intelligenza artificiale è fondamentale per garantire il successo dei tuoi progetti di machine learning.
Progettiamo e implementiamo architetture moderne sui principali provider Cloud, tra cui Google BigQuery, Snowflake, Amazon Redshift e Databricks. La nostra metodologia “Vendor Lock-in Free” assicura che l’infrastruttura rimanga flessibile e non vincolata a un singolo fornitore.
Essendo un’azienda intelligenza artificiale, sappiamo bene che nessun algoritmo o analisi avanzata può funzionare senza fondamenta solide. Per questo sviluppiamo pipeline ETL/ELT robuste utilizzando linguaggi come Python e SQL, orchestrate da strumenti avanzati come Apache Airflow o Dagster. Questo approccio ci permette di estrarre dati da database SQL tradizionali o sistemi ERP/CRM complessi, normalizzandoli in un’unica “Single Source of Truth” (un’unica fonte di verità aziendale) perfettamente pulita e pronta per alimentare sia i tuoi processi decisionali che i futuri modelli predittivi.
Gli Agenti AI e i sistemi RAG (Retrieval-Augmented Generation) sono efficaci solo se alimentati da dati puliti, aggiornati e ben indicizzati. Un’infrastruttura di Data Engineering solida trasforma il patrimonio informativo aziendale in un asset pronto per essere interrogato dai Large Language Models, eliminando le allucinazioni e migliorando la precisione delle risposte.